
Web semantico
Il web semantico consiste nella trasformazione del World Wide Web in un ambiente dove i documenti pubblicati sono associati ad informazioni e dati che ne specificano il significato e il contesto in un formato adatto all’interrogazione, l’interpretazione e l’elaborazione automatica. L’interpretazione del contenuto dei documenti rende possibili ricerche sempre più evolute, basare su reti di relazioni e connessioni tra documenti secondo logiche più elaborate rispetto al semplice collegamento ipertestuale.
Tim Berners Lee ha trasformato Internet nel Web partendo dal principio che se Internet era stato capace di mettere in contatto macchine in tutto il mondo, il Web deve mettere in relazione persone in tutto il mondo. Ma le persone hanno bisogno di dare significato a ciò che sanno e che fanno, a ciò che cercano e che trovano, che acquistano e che vendono. E così accanto all’interfaccia grafica che rende la navigazione intuitiva e naturale, si sviluppa la semantica che interpreta i significati dei messaggi e dei contenuti in entrata e in uscita dai sistemi.
Nella vita comune tutti noi usiamo immagini e parole senza preoccuparci del loro significato, che modifichiamo di volta in volta in base alla situazione, al contesto, agli interlocutori e ai compiti da svolgere. “Cane” può significare “animale domestico”, ma anche “attore di scarso valore”, può riferirsi ad un animale specifico, alla classe dei canidi, alla sottoclasse del cane-lupo. Le macchine non hanno ancora la nostra adattabilità mentale, hanno bisogno di maggiore precisione per non fare confusione e ridurre al minimo le ambiguità. Ecco dunque che la parola “cane” deve contenere altre informazioni su di sé, e se deve indicare un cane specifico ha bisogno di un riferimento che appartiene solo a quel cane (è il concetto di URL o URI, unique resource locator o identifier, identificatore unico di risorsa).
Possiamo accedere alle informazioni contenute in internet attraverso l’url che conduce direttamente ad un oggetto informativo come un sito o una pagina web, oppure possiamo cercarle con i motori di ricerca. Il web semantico ha sviluppato algoritmi e programmi che hanno trasformato il Web da un contenitore in cui era abbastanza difficile trovare dei contenuti, ad un ambiente in cui ogni elemento pubblicato, sia esso un video, una foto o un documento, è facilmente trovabile grazie alle associazioni tra informazioni e dati che permettono di rintracciare tutto quanto sia connesso ad un determinato argomento, parola o dato.
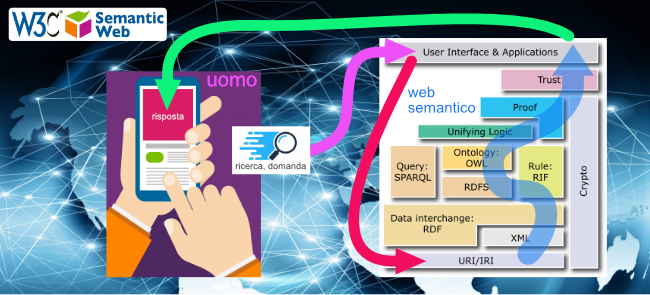
Il problema di base è come rendere univoco il linguaggio con cui la macchina riceve le domande e fornisce le risposte, e di renderlo altresì comprensibile all’essere umano. Il web semantico comprende ciò che gli viene chiesto. Prima del web semantico le ricerche andavano fatte scrivendo le parole chiave esattamente, e combinandole con operatori booleani. Oggi per fare una ricerca in rete basta scrivere quello che cerchiamo con parole nostre, come se lo chiedessimo ad una persona, per ottenere molti risultati pertinenti. Più l’algoritmo comprende le domande, migliori saranno le risposte.
I tre elementi chiave del web semantico sono query (domande, ricerche), rule (regole, criteri di ricerca, archiviazione e classificazione), trust (verità e affidabilità delle risposte).
Il web semantico si è sviluppato in due fasi, la prima sintetica e basata sulle ontologie dei dati, la seconda analitica e basata sulle relazioni fra dati. Gli elementi fondamentali degli algoritmi di ricerca sono l’organizzazione della conoscenza che identifica e relaziona i diversi elementi utili alla ricerca, la rappresentazione della conoscenza che descrive i dati, la strumentazione che include una serie di programmi per comprendere, leggere ed operare su tutte le rappresentazioni trovate in rete.
Il web semantico non si limita ad offrire la risposta fredda alle parole chiave immesse nel motore, ma individua, grazie a sistemi di intelligenza artificiale, le diverse necessità che può avere chi sta facendo la sua ricerca.
Il web semantico ha una struttura tecnica a molti strati, lo strato di base, gli strati intermedi e lo strato finale. Lo strato di base è ben consolidato, quello finale è in pieno sviluppo, per renderlo sempre più amichevole nei confronti dell’uomo.
Una risorsa web deve rendersi reperibile. Per farlo deve contenere informazioni su se stessa leggibili dalle macchine, i metadati. Il web semantico è un’infrastruttura basata su metadati per ragionare sul web. Per esempio una figura come la foto di un fiore ha un testo esplicativo che descrive il fiore, e metadati che lo classificano e lo corredano di informazioni sulla misura, il peso, la provenienza, ecc. I metadati sono un gruppo di dichiarazioni riferito ad una risorsa, che deve essere stabile o aggiornata. Il linguaggio web per descrivere tutto ciò è l’XML (Extensible Markup Language). L’RDF (Resource Description Framework) invece è un modello generale per dichiarazioni modellate con risorse (uri, elemento, ecc.), proprietà (relazioni fra due risorse), dichiarazioni triple (soggetto, proprietà, oggetto). Può essere espresso in XML o altre sintassi. Si occupa delle relazioni fra individui, mentre l’RDFS (RDF Schema) si dedica a classi e sottoclassi. OWL (Ontology Web Language) è un linguaggio di rappresentazione delle conoscenze costruito sul modello RDF e dedicato alla definizione di ontologie web strutturate e alla descrizione di una classe secondo le sue caratteristiche e priorità.
Tutti questi linguaggi sono sviluppati e promossi dal W3C (World Wide Web Consortium), un ente no profit che ha lo scopo di favorire la compatibilità delle tecnologie web secondo il motto “Un solo web dappertutto e per tutti”.
Il web semantico usa un supporto di ontologie per definire la terminologia di un contesto specifico, le limitazioni sulle proprietà, le caratteristiche logiche delle proprietà, le equivalenze dei termini fra le ontologie, ecc.
Le ontologie sono definite per classi o gruppi di individui e per gerarchie o sotto-classi. Le proprietà sono definite da limitazioni nel loro dominio e da specializzazione. Il modello generale è “a cipolla”, con specifiche sempre più complesse.