
Clustering
Se analizziamo un insieme di oggetti e raggruppiamo tutti quelli rossi, tutti quelli gialli, oppure tutti quelli rotondi, o quelli più grandi o i più pesanti, facciamo un’operazione di clustering, che significa estrarre da un insieme di dati elementi con qualche caratteristica omogenea e farne dei gruppi in base alle caratteristiche scelte.
Nelle reti neurali e nei sistemi di intelligenza artificiale gli algoritmi di clustering misurano la distanza fra i dati analizzati, secondo parametri scelti. I dati meno distanti sono quelli che più si assomigliano rispetto alla caratteristica presa in considerazione. La qualità di un cluster dipende dal modo in cui viene calcolata la distanza e dalle soglie in base alle quali un elemento viene incluso o meno nel cluster.
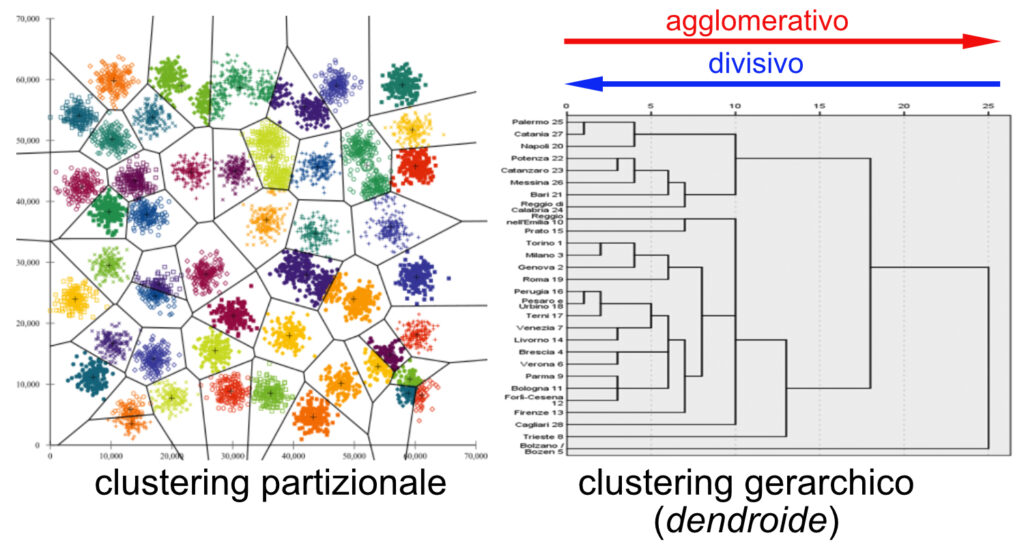
Nel clustering agglomerativo le aggregazioni possono esser fatte dal basso verso l’alto, ossia dai dati indistinti verso aggregazioni sempre più ampie, in base alle distanze calcolate e alle soglie di inclusione. Nel clustering divisivo si procede dall’alto verso il basso, quando l’insieme dei dati viene considerato come un unico cluster che viene successivamente suddiviso in cluster sempre più piccoli e specifici.
Il clustering è esclusivo (hard) se ogni elemento può essere assegnato ad uno e ad un solo gruppo, in modo che i cluster risultanti non possono avere elementi in comune. E’ non-esclusivo (soft) se un elemento può appartenere a più cluster, con gradi di appartenenza diversi: è detto anche fuzzy clustering, riferendo il metodo alla logica fuzzy. Considerando l’algoritmo usato per dividere lo spazio, si parla di clustering partizionale o non gerarchico, se si tiene conto della distanza da un centro significativo, o gerarchico, se il criterio per attribuire un elemento ad un cluster obbedisce ad una struttura ad albero.