
Text to image
Un programma text to image genera output visivi da input verbali.
L’intelligenza artificiale mette a disposizione programmi ormai alla portata di tutti in cui si digita la descrizione verbale di un’immagine e si ottiene l’immagine richiesta con una buona risoluzione e un livello di verosimiglianza fotografica.
Programmi di questo tipo usano le reti neurali e l’apprendimento automatico per analizzare in base alle richieste enormi quantità di immagini con relative didascalie in modo da selezionare immagini o particolari pertinenti e combinarli per soddisfare la richiesta verbale.
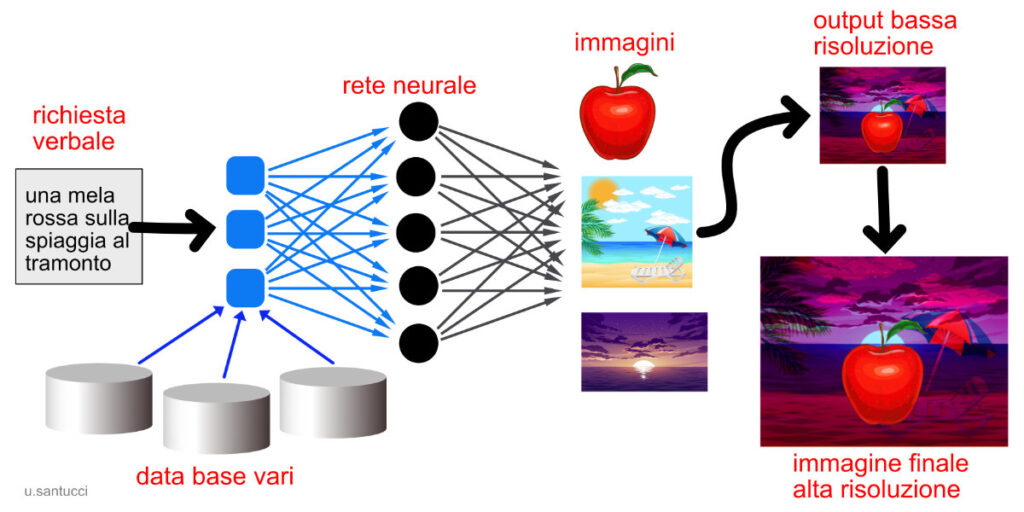
Per comprendere come funziona il processo, eccone uno schema grafico. Se il programma riceve la richiesta “una mela rossa sulla spiaggia al tramonto”, selezionerà alcuni tipi di mele rosse e di spiagge al tramonto, poi sceglierà una mela e la combinerà con la spiaggia illuminando il tutto con luce da tramonto. Le immagini saranno scelte e combinate a bassa risoluzione, e poi trasformate ad alta risoluzione da modelli che ne integrano i dati insufficienti. La qualità dell’immagine finale dipende dal tipo di programmi utilizzati, ma verosimilmente fra qualche tempo anche i programmi di uso comune saranno in grado di generare output della risoluzione voluta.
Come accade per i motori di ricerca, i risultati dipendono dalla qualità delle domande, che in base alle risposte devono essere precisate man mano, o formulate in modo diverso. Tuttavia i programmi attuali sono già in grado di comprendere il contesto geografico e storico (“una Fiat 1100 anni ’50 davanti al Colosseo”), dedurre dettagli e complementi (se chiedo una luce, farà le ombre), mettere gli oggetti in prospettiva e fare estrusioni tridimensionali, ma anche di combinare immagini di qualsiasi genere inventandone di nuove, e produrre immagini alla maniera di stili e di artisti famosi (una giovane donna leonardesca, o un tavolo in stile liberty).

Per avere un’idea delle possibilità di programmi del genere ricorro ad alcune immagini di due amici fotografi che stanno studiando con entusiasmo e curiosità programmi come Midjourney o Dall-E. Questa è un’immagine di Alessandro Ghezzer, fotografo trentino specializzato nelle foto di montagna ed escursionismo, generata dalla richiesta di una casa da favola in una foresta verso sera.

Ancora Ghezzer ha chiesto immagini di ricchi e poveri nella Londra di fine ottocento, ottenendo veri e propri racconti fotografici buoni per illustrare i romanzi di Dickens. Alcuni particolari lasciano ancora a desiderare – specialmente le mani – ma i risultati nell’insieme sono stupefacenti, non solo per la correttezza storica, ma anche per il sentimento di apatica sopportazione dei poveri e di orgogliora arroganza dei ricchi. Ovviamente il programma non ha emozioni e non può metterle nelle immagini che produce, ma siamo noi con la nostra sensibilità a vedere le emozioni nelle immagini generate dalla rete neurale artificiale.

Patrizia Savarese, fotografa romana, ha generato queste bellissime rose che piombano dentro un vaso fatto di acqua, partendo da poche parole come “rose”, “acqua”, “schizzi”, “liquido”.

Patrizia ha dato anche un tema generale come “cambiamento climatico”, chiedendo via via i concetti di scioglimento dei ghiacci, esplosione, acqua e fuoco, e ottenendo la sequenza di globi terrestri.
Artisti, fotografi, e in genere tutti coloro che, per un verso o per l’altro, sono interessati alla produzione o al consumo di immagini, gioiscono di tali opportunità, o si chiedono dove andremo a finire, e che cosa faranno gli umani ex creatori e produttori di immagini ormai totalmente inventate e prodotte dalle macchine.
Come tutte le tecnologie, anche questa tende a togliere agli umani il peso e la noia di attività ripetitive, e a rendere facili e alla portata di tutti cose che finora erano difficili e riservate agli specialisti. Pensiamo solo allo smartphone, che ha messo nelle tasche di ognuno di noi una fotocamera che praticamente fa tutto da sola (messa a fuoco, esposizione, velocità di scatto, stabilizzazione dei movimenti) e, mostrandoci subito il risultato, ci permette di correggerci e di produrre foto quanto meno accettabili. Il text to image è un ulteriore passo in cui tutti saranno in grado, come art director, di visualizzare qualsiasi idea, concetto o descrizione. Il dilettante si accontenterà, il professionista ci metterà del suo per integrare ciò che ottiene dal programma intelligente, l’utilizzatore professionale di immagini come i picture editor, i giornalisti, gli art director, i responsabili di comunicazione, avrà in mano uno strumento con cui potrà provare da solo la visualizzazione delle proprie idee, per poi fare una richiesta più precisa a fotografi, illustratori e infografici.
Il problem solving ci spinge a chiederci, di fronte a questi programmi, quale sarà il ruolo dei creatori e produttori di immagini, e in che cosa potrà consistere l’apporto dell’uomo. Sarà meglio usare questi programmi per compiti di routine come fotomontaggi e ritocchi, visualizzazioni rapide, sequenze animate, oppure spingerli ai limiti dell’immaginazione per vedere che cosa combinano? Fino a quando l’uomo sarà in grado di fare cose che le macchine non possono fare? L’uomo sarà sempre necessario per dare un senso a ciò che fanno le macchine, giacché esse lo fanno per lui, non per se stesse? E’ troppo presto per rispondere, ma è opportuno cominciare a porsi le domande.